 模板管理与配置
模板管理与配置
# 模板管理系统使用指南
# 🔍 概述
# 什么是模板?
模板是一套预设好的网页数据采集规则,类似于"数据采集的说明书"。正确配置模板后,系统能自动从网站中提取您需要的信息,无需手动复制粘贴或重复操作。
# 为什么需要使用模板?
- 提高效率:一次配置,多次使用,避免重复工作
- 保证数据一致性:统一的数据格式,便于后续处理和分析
- 适应不同网站:可针对电商、社交媒体等不同类型网站定制采集策略
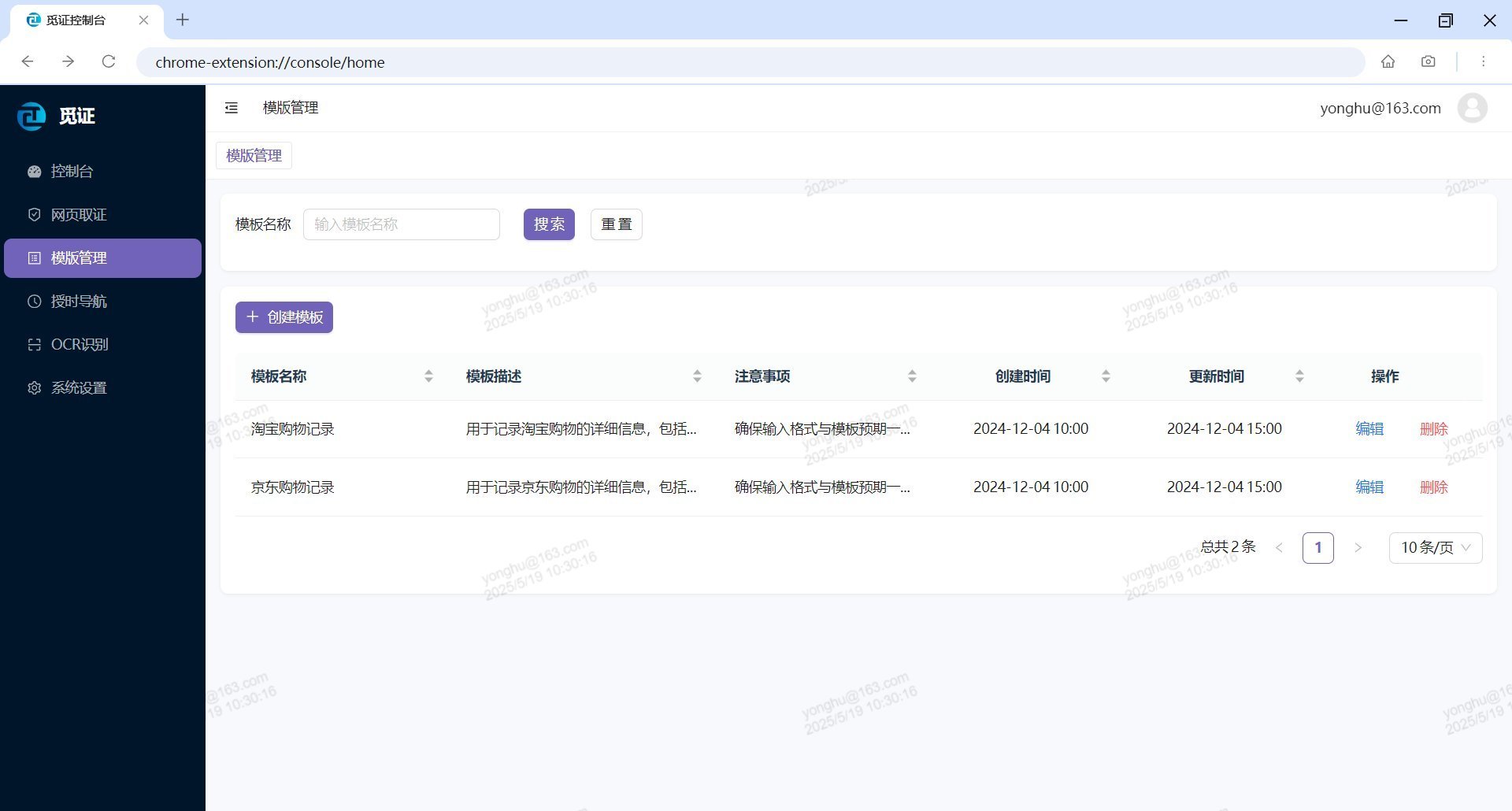
# 📋 模板管理界面概览
在模板管理页面,您可以进行以下操作:
- 创建新模板:根据特定网站结构设计采集规则
- 编辑已有模板:修改或优化现有模板配置
- 删除不需要的模板:移除过时或不再使用的模板
# 📋 模板基础信息
每个模板都包含以下基本信息,帮助您识别和管理模板:
| 字段名称 | 说明 | 示例 | 填写建议 |
|---|---|---|---|
| id | 模板唯一标识符 | T20241201-001 | 系统自动生成,无需手动填写 |
| templateName | 简明描述模板用途 | 淘宝购物记录 | 使用"网站名+功能"格式命名 |
| templateDescription | 详细说明模板功能 | 用于记录淘宝购物的详细信息,包括时间、商品、金额等 | 写明可采集的数据类型和应用场景 |
| templateNote | 操作提示和注意事项 | 确保输入格式与模板预期一致,以避免数据错误 | 包含前置条件和特殊限制 |
小贴士:好的命名和详细的描述可以帮助您快速找到所需模板,特别是当模板数量增多时。
# 核心配置项详解
模板配置主要分为三大部分,下面将逐一说明:
# 1. 基础设置
# 1.1 目标网址配置
这是模板的起始点,指定需要采集数据的网站地址。
- 配置项:
baseUrl - 示例值:
https://buyertrade.taobao.com - 如何配置:
- 打开需要采集的网站
- 复制浏览器地址栏中的网址(确保是列表页的基础地址)
- 粘贴到配置项中
注意:如果网站改版或地址变更,需及时更新此配置,否则采集将失败。
# 1.2 任务队列配置
模板支持配置多个任务,每个任务有其特定用途。在任务列表(taskList)中,可以设置各种类型的任务。
- 类型说明:目前仅支持
pageLoader(页面加载与数据解析) - 适用场景:需要浏览多个页面并从中提取数据的情况
- 何时选择:采集需要翻页的数据列表(如订单历史、商品列表、商品详情等)
# 2. 页面解析配置
# 2.1 列表页解析及数据提取
列表页通常包含多条记录的概要信息(如订单列表、商品列表等)。

配置步骤:
# 2.1.1 分页配置
大多数数据都分布在多个页面,需要配置分页规则进行翻页采集。
分页方式选择:
根据网站的分页实现方式选择合适的配置:
- 按钮式翻页:网页有明确的"下一页"按钮
{ "pageHelperType": "nextPrevButton", "pageHelperSelector": { "nextPrevButton": { "XPath": "", "CSSPath": ".simple-pagination-mod__container___h-3an .button-mod__button___2HDif[data-reactid=\".0.5.1.0.1\"]" }, "total": { "XPath": "", "CSSPath": "" // 如需检测总页数,在此填写总页数元素的选择器 } } }
分页范围设定:
控制采集的页数范围:
{
"pageHelperConfig": {
"startPageSize": 1, // 从第1页开始
"endPageSize": 1 // 到第1页结束(只采集第1页)
},
"setting": {
"upLimit": 50 // 最大翻页次数,防止无限循环
}
}
实用技巧:
- 首次测试时,建议设置较小的页面范围(如只取第1页)
- 确认配置无误后,可修改
endPageSize扩大范围进行完整采集 - 如果知道总页数,可以配置
total选择器自动判断终止条件
# 2.1.2 HTML快照保存配置
开启HTML快照保存:设置isSaveHtml=true,启用网页HTML快照保存功能,将保存网页的源码作为一个html文件,用于特定的场景下使用。
{
"isSaveHtml": true
}
使用场景:
- 数据取证:保存原始网页作为数据来源的证据
- 问题排查:当数据采集异常时,可通过HTML快照分析原因
- 离线分析:不依赖网络连接即可分析网页结构
# 2.1.3 数据输出配置
定义输出文件:
{
"outputFileName": "淘宝订单数据", // 输出文件名称
"outputFileType": "excel", // 输出文件类型,支持excel、csv等
"mergeState": true // 是否合并多页数据到同一文件
}
字段解释:
outputFileName:指定生成的数据文件名称outputFileType:指定输出文件格式,常用格式有excel、csv、json等mergeState:设为true时,多页数据会合并到一个文件中;设为false时,每页数据生成单独的文件
# 2.1.4 数据表格配置
配置数据表格:
{
"sheetList": [
{
"sheetName": "淘宝订单列表信息", // Excel工作表名称
"columns": [
{
"headerName": "订单号", // 表头名称
"selector": { // 数据选择器
"XPath": "", // XPath选择器(可选)
"CSSPath": ".bought-wrapper-mod__table___3xFFM .bought-wrapper-mod__head___2vnqo .bought-wrapper-mod__head-info-cell___29cDO span:nth-child(3)" // CSS选择器
}
},
{
"headerName": "商品名称",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__table___3xFFM tbody:nth-child(3) tr:nth-child(1) .sol-mod__no-br___toLPG:nth-child(1) .suborder-mod__production___3WebF p a span:nth-child(2)"
}
},
{
"headerName": "订单时间",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__create-time___yNWVS"
}
},
{
"headerName": "总金额",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__table___3xFFM td strong span:nth-child(2)"
}
}
]
}
]
}
字段解释:
sheetName:Excel工作表的名称columns:定义要采集的数据列headerName:表格的列标题selector:用于定位网页元素的选择器XPath:使用XPath语法的选择器(适合复杂结构)CSSPath:使用CSS选择器语法(推荐,更易于获取)
如何获取选择器:
- 在Chrome浏览器中打开目标网页
- 右键点击要提取的元素,选择"检查"
- 在开发者工具中右键点击对应HTML元素,选择"Copy > Copy selector"
- 粘贴到配置的CSSPath中
技巧:先确定要采集的字段,然后逐一获取对应的选择器。测试时建议先采集少量数据验证配置是否正确。
# 2.2 详情页数据提取
有时列表页信息不够详细,需要进入每条记录的详情页获取更多信息。

配置步骤:
# 2.2.1 详情页入口配置
详情页入口配置指定如何从列表页进入到详情页,通常是通过点击某个链接或按钮。
详情页类型选择:
目前系统支持以下详情页访问方式:
- 链接点击方式:通过点击列表页中的链接进入详情页
{ "pageDetailType": "linkDetail", "pageDetailSelector": { "XPath": "", "CSSPath": ".bought-table-mod__table___3Onwb.bought-wrapper-mod__table___3xFFM > tbody:nth-of-type(2) > tr > td:nth-of-type(6) a#viewDetail" } }
字段解释:
pageDetailType:详情页访问方式,常用值为linkDetail(链接点击方式)pageDetailSelector:指定要点击的元素选择器XPath:使用XPath语法定位元素CSSPath:使用CSS选择器语法定位元素(推荐)
实用技巧:
- 选择稳定且唯一的元素作为详情页入口,避免选择可能变化的元素
- 如果详情页入口在列表中重复出现(如每行都有"查看详情"按钮),确保选择器能准确匹配到对应行的按钮
# 2.2.2 HTML快照保存配置
与列表页类似,详情页也支持HTML快照保存功能。
{
"isSaveHtml": true // 开启详情页HTML快照保存
}
使用场景:
- 保存详情页原始HTML用于数据验证和问题排查
- 当详情页数据结构复杂时,保存HTML便于后续分析
- 对于需要取证的场景,保留原始页面内容作为证据
# 2.2.3 数据输出配置
详情页的数据输出配置决定了如何处理和保存从详情页获取的数据。
{
"outputFileName": "", // 可留空,使用与列表页相同的输出文件
"outputFileType": "", // 可留空,使用与列表页相同的类型
"mergeState": true,
"mergeRule": "singleOne" // 数据合并规则
}
字段解释:
outputFileName:输出文件名,留空则使用列表页配置的文件名outputFileType:输出文件类型,留空则使用列表页配置的文件类型mergeState:是否将详情页数据与列表页数据合并mergeRule:详情页数据合并规则,可选值:singleOne:每条记录的详情单独合并(推荐,一对一关系)singlePage:整页详情合并(一对多关系)multiPage:多页详情合并(多对多关系)
数据合并规则说明:
singleOne:适用于每个列表项对应一个详情页的情况,如商品列表中每个商品都有自己的详情页singlePage:适用于一个列表页对应一个汇总详情页的情况multiPage:适用于复杂场景,需要从多个详情页收集数据并合并
# 2.2.4 数据表格配置
详情页数据表格配置定义了从详情页提取哪些数据字段。
{
"sheetList": [
{
"sheetName": "订单详情", // Excel工作表名称
"columns": [
{
"headerName": "物流状态", // 表头名称
"selector": { // 数据选择器
"XPath": "", // XPath选择器(可选)
"CSSPath": ".logistics-status" // CSS选择器
}
},
{
"headerName": "收货地址",
"selector": {
"XPath": "",
"CSSPath": ".address-info"
}
},
{
"headerName": "支付方式",
"selector": {
"XPath": "",
"CSSPath": ".payment-method"
}
}
]
}
]
}
字段解释:
sheetName:Excel工作表名称,建议与列表页使用不同名称以区分columns:定义要采集的数据列headerName:表格的列标题selector:用于定位网页元素的选择器XPath:使用XPath语法的选择器CSSPath:使用CSS选择器语法
完整的详情页配置示例:
{
"pageDetailRule": {
"isSaveHtml": true,
"pageDetailType": "linkDetail",
"pageDetailSelector": {
"XPath": "",
"CSSPath": ".bought-table-mod__table___3Onwb.bought-wrapper-mod__table___3xFFM > tbody:nth-of-type(2) > tr > td:nth-of-type(6) a#viewDetail"
},
"dataParseRule": {
"outputFileName": "",
"outputFileType": "",
"mergeState": true,
"mergeRule": "singleOne",
"sheetList": [
{
"sheetName": "订单详情",
"columns": [
{
"headerName": "物流状态",
"selector": {
"XPath": "",
"CSSPath": ".logistics-status"
}
},
{
"headerName": "收货地址",
"selector": {
"XPath": "",
"CSSPath": ".address-info"
}
}
]
}
]
},
"config": {}
}
}
# 3. 系统设置
# 3.1 安全配置
防止被目标网站识别为爬虫的设置:
{
"security": {
"requestInterval": "2000±500ms", // 请求间隔2秒±500毫秒,模拟人工操作
"headerRotation": {
"User-Agent": "RotatingPool", // 随机切换浏览器标识
"Referer": "DynamicGenerate" // 动态生成来源页面
}
}
}
为什么需要安全配置:许多网站会检测异常访问行为,如果请求过于频繁或规律,可能会被识别为自动程序并被限制访问。
# 3.2 性能配置
控制系统资源使用:
{
"performance": {
"concurrencyLimit": 8, // 最大同时进行的任务数
"resourceQuota": {
"memory": "512MB", // 单任务内存限制
"cpu": 0.7 // CPU使用率上限
}
}
}
配置建议:
- 高配置电脑可适当提高并发数(8-12)
- 低配置电脑应降低并发数(2-4)避免系统卡顿
- 长时间运行任务时,应适当降低资源占用率
# 📝 完整模板配置示例
以下是一个完整的淘宝订单数据采集模板示例,包含了所有必要的配置项:
{
"id": "T20241201-001",
"templateName": "淘宝购物记录",
"templateLocation": "",
"templateDescription": "用于记录淘宝购物的详细信息,包括时间、商品、金额等。",
"templateNote": "确保输入格式与模板预期一致,以避免数据错误。",
"templateUsageCount": "2500",
"createBy": "admin",
"createTime": "2024-12-04 10:00",
"updateBy": "editor01",
"updateTime": "2024-12-04 15:00",
"imageUrl": "https://example.com/images/templates/taobao_shopping.jpg",
"templateConfig": {
"baseUrl": "https://buyertrade.taobao.com",
"taskList": [
{
"type": "pageLoader",
"pageHelperRule": {
"pageHelperType": "nextPrevButton",
"pageHelperSelector": {
"nextPrevButton": {
"XPath": "",
"CSSPath": ".simple-pagination-mod__container___h-3an .button-mod__button___2HDif[data-reactid=\".0.5.1.0.1\"]"
},
"total": {
"XPath": "",
"CSSPath": ""
}
},
"pageHelperConfig": {
"startPageSize": 1,
"endPageSize": 1
},
"setting": {
"upLimit": 50
}
},
"pageListRule": {
"isSaveHtml": true,
"dataParseRule": {
"outputFileName": "淘宝订单数据",
"outputFileType": "excel",
"mergeState": true,
"sheetList": [
{
"sheetName": "淘宝订单列表信息",
"columns": [
{
"headerName": "订单号",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__table___3xFFM .bought-wrapper-mod__head___2vnqo .bought-wrapper-mod__head-info-cell___29cDO span:nth-child(3)"
}
},
{
"headerName": "商品名称",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__table___3xFFM tbody:nth-child(3) tr:nth-child(1) .sol-mod__no-br___toLPG:nth-child(1) .suborder-mod__production___3WebF p a span:nth-child(2)"
}
},
{
"headerName": "订单时间",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__create-time___yNWVS"
}
},
{
"headerName": "总金额",
"selector": {
"XPath": "",
"CSSPath": ".bought-wrapper-mod__table___3xFFM td strong span:nth-child(2)"
}
}
]
}
]
},
"config": {}
},
"pageDetailRule": {
"isSaveHtml": true,
"pageDetailType": "linkDetail",
"pageDetailSelector": {
"XPath": "",
"CSSPath": ".bought-table-mod__table___3Onwb.bought-wrapper-mod__table___3xFFM > tbody:nth-of-type(2) > tr > td:nth-of-type(6) a#viewDetail"
},
"dataParseRule": {
"outputFileName": "",
"outputFileType": "",
"mergeState": true,
"mergeRule": "singleOne",
"sheetList": [
{
"sheetName": "订单详情",
"columns": [
{
"headerName": "物流状态",
"selector": {
"XPath": "",
"CSSPath": ".logistics-status"
}
},
{
"headerName": "支付方式",
"selector": {
"XPath": "",
"CSSPath": ".payment-method"
}
}
]
}
]
},
"config": {}
},
"baseConfig": {
"security": {
"requestInterval": "2000±500ms",
"headerRotation": {
"User-Agent": "RotatingPool",
"Referer": "DynamicGenerate"
}
},
"performance": {
"concurrencyLimit": 8,
"resourceQuota": {
"memory": "512MB",
"cpu": 0.7
}
}
}
}
]
}
}
# ⚠️ 常见问题与解决方案
# 问题1:无法获取数据或数据不完整
可能原因:
- 选择器配置错误
- 网站结构已变更
- 数据需要登录才能访问
解决方案:
- 重新检查并更新选择器
- 确认是否已正确登录网站
- 检查网站是否有反爬机制,适当增加请求间隔
# 问题2:"页面走丢啦"或访问受限
可能原因:
- 请求频率过高触发网站防护
- IP被临时限制访问
解决方案:
- 增加请求间隔时间(建议3000ms以上)
- 优化User-Agent配置,增加随机性
- 降低并发数,减少短时间内的请求量
# 问题3:模板运行缓慢或系统卡顿
可能原因:
- 并发任务过多
- 资源配额设置过高
解决方案:
- 减少并发数(建议从2-4开始测试)
- 降低内存和CPU资源配额
- 分批次运行大量数据采集任务
# 📈 优化模板的建议
# 采集效率优化
- 精确定位元素:使用ID选择器(如
#order-id)比类选择器(如.order-item)更快 - 减少详情页访问:如果列表页信息已满足需求,可不配置详情页采集
- 按需保存HTML快照:只在取证或调试阶段开启HTML快照保存(
isSaveHtml=true),正式运行时如无需保存证据可关闭以提升性能
# 稳定性优化
- 双重定位机制:同时配置XPath和CSS选择器,提高元素查找成功率
- 合理设置超时时间:增加页面加载超时时间,应对网络波动
- 添加重试机制:对失败的请求自动重试,提高任务完成率
# 模板维护技巧
- 定期验证模板:网站可能更新结构,建议每月检查模板有效性
- 版本管理:重大修改前备份模板,方便回退
- 模块化设计:将公共配置提取为模板片段,便于复用和维护
# 🚀 进阶使用技巧
# 动态变量使用
模板支持以下动态变量,可在配置中灵活使用:
{date}:当前日期,格式为YYYY-MM-DD{time}:当前时间,格式为HH:MM:SS{timestamp}:当前时间戳{random}:随机数字,可用于避免生成重名文件
示例:
{
"outputFileName": "taobao_orders_{date}_{random}"
}
# 条件解析规则
针对不同情况的页面元素,可使用条件选择器:
{
"selector": {
"condition": [
{
"when": ".out-of-stock",
"then": {
"CSSPath": ".out-of-stock-price"
}
},
{
"when": ".in-stock",
"then": {
"CSSPath": ".normal-price"
}
}
]
}
}
# 数据后处理
对提取的数据进行清洗和转换:
{
"columns": [
{
"headerName": "价格",
"selector": {
"CSSPath": ".price"
},
"transform": [
{
"type": "replace",
"pattern": "¥",
"replacement": ""
},
{
"type": "toNumber"
}
]
}
]
}
# 📚 学习资源和参考
通过本指南的学习,您应该已经掌握了模板配置的核心知识。从简单的列表页采集到复杂的多页面数据提取,都可以通过合理配置模板来实现。记住,模板配置是一个不断优化的过程,随着使用经验的积累,您将能创建更高效、更稳定的数据采集方案。